Readable code: Writing future-proof applications

By Florian Maas on February 27, 2024
Estimated Reading Time: 7 minutes
A misconception regarding code that I hear all too often is that code is good when it's working; i.e. it is doing what it's supposed to be doing. While that is obviously an important aspect of code, it says absolutely nothing about the quality and the maintainability of the code.
In my opinion, the most important aspect of code is that code should be easy to read. I would even argue that readability is more important than functionality.
To illustrate, consider a project that works properly but which consists of code that is hard to read; while there may not be a problem today, problems arise when a new feature should be added to the project or when the project contains a bug that should be solved. Not only will it be difficult to make the required changes due to the poorly readable code, the probability of introducing more issues into the codebase while modifying it is also high. Now consider a project that is well written and easy to read, but it does not (yet) do what it should be doing. That is a problem today, but since the code is easy to interpret, modyifing it to improve its functionality should be an achievable task.
So in the first scenario, we have zero problems today, but potentially a large amount of problems in the future, whereas in the latter scenario we have a problem today, but we will likely have few problems in the future.
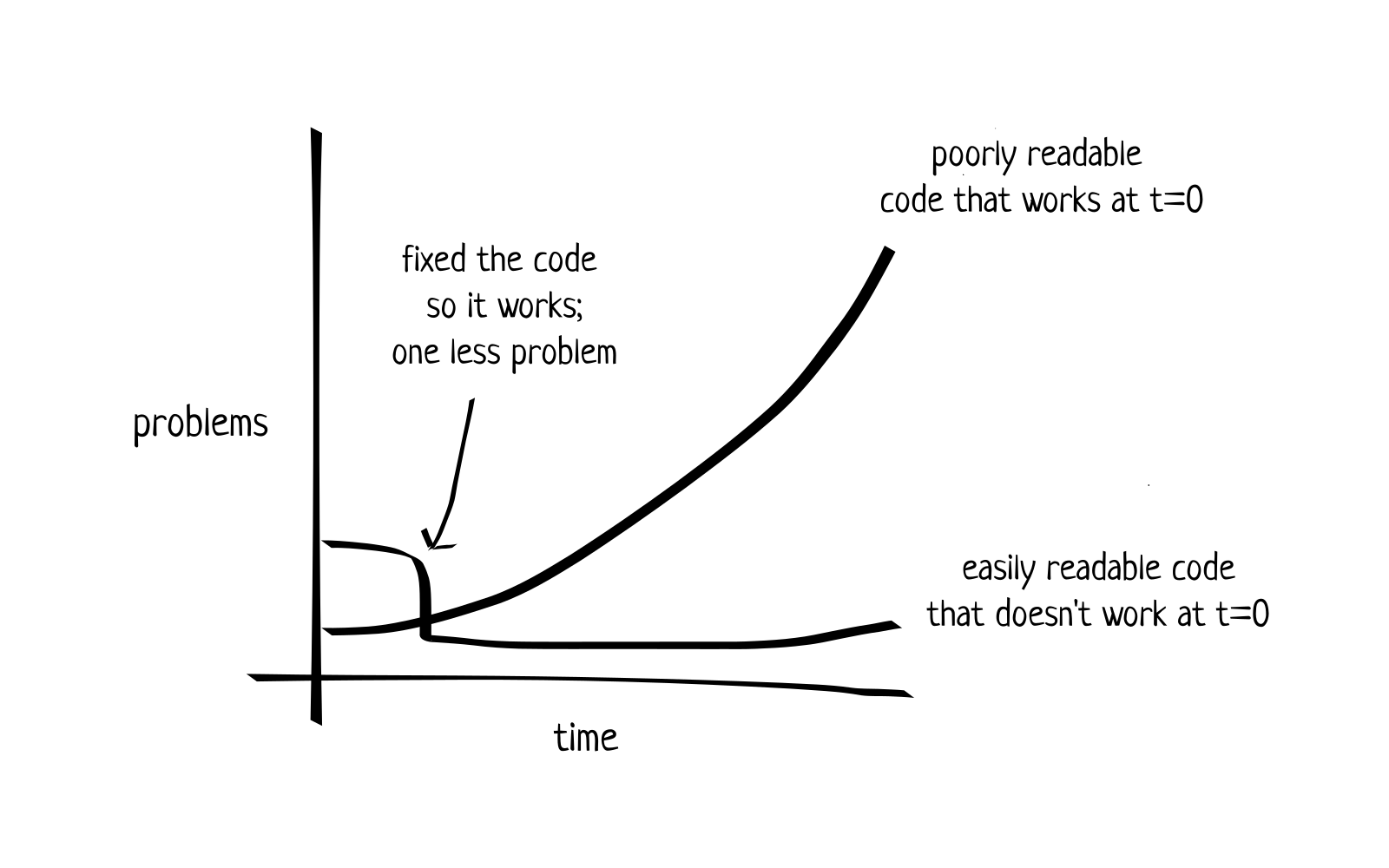
This example illustrates that making code readable is just as important as - or even more important than - making code work. This of course brings us to the million-dollar question...
How to write readable code?
Many books have been written that help to answer this question, of which "Clean Code" by Robert C. Martin is probably the most well-known. There are also principles like DRY or SOLID that when properly applied will help a developer write more readable code. I am not going to pretend to have a better answer than the existing resources and principles out there, so I highly recommend reading up on those if you have not done so yet. In addition, I'd like to share one guideline that I always try to follow when writing code which helps me to keep my code readable, which is:
Code should be readable in the same way that this blog post is readable.
That is to say; code should consist of words, and when read out loud from top to bottom, it should tell us what it is doing.
Ideally, code should read like a step-by-step manual; the body of a high-level function should provide a clear overview of what the code is doing, and preferably it should be readable by someone who has no prior knowledge of code or software development. It should act like a summary, detailing which steps are to be taken. To get a more detailed view of what is happening, one should be able to read the functions that are being called by the high-level function.
As an example, let's assume we have an application that processes an order. The processing of an order can be divided into four logical steps:
In this case, we would probably like to create a class called OrderProcessor with a method called process that contains the
logic at the highest level of abstraction. For example, our class could look like this:
class OrderProcessor:
[...]
def process(self):
self._check_inventory_levels()
self._process_payment()
self._update_inventory()
self._arrange_shipping()
We can see that breaking our code into distinct, clear parts and making a separate function for each part helps make our code easy to read; it is immediately clear what the code aims to do by reading it, even for someone without any prior knowledge about Python or our application.
We can take this example a step further, and see for example that the process_payment function can also be divided into three logical steps:
In this case too, we have a set of distinct functions that are related and that can be logically grouped together.
We would probably want to create a PaymentProcessor class, with a process function that calls the lower level functions _validate_credit_card, _charge_credit_card,
and _log_payment_transaction.
The two primary reasons for creating a separate class for these methods instead of placing them in the OrderProcessor class are
reusability and maintainability: We can now reuse our payment processing logic aywhere in our code, and if anything changes
in the logic, we only need to change it in one place.
Our new PaymentProcessor class could look like this:
class PaymentProcessor:
def __init__(self, credit_card_number: str, amount: float):
self.credit_card_number = credit_card_number
self.amount = amount
def process(self):
self._validate_credit_card()
self._charge_credit_card()
self._log_payment_transaction()
and our updated OrderProcessor class:
class OrderProcessor:
[...]
def process(self):
self._check_inventory_levels()
self._process_payment()
self._update_inventory()
self._arrange_shipping()
def _process_payment(self):
PaymentProcessor(
credit_card_number = order.credit_card_number,
amount = order.amount
).process()
[...]
And again we see that we keep the code readable by simply dividing the logic and creating a clearly-named function for each separate piece of logic. If I were to give the piece of code we just wrote to a friend who has never seen a line of code in their life, they would likely still be able to tell me what this code is doing at a high level.
For me personally, keeping in mind that my code should be readable like illustrated above helps me write better code. Maybe the same holds for you, maybe it doesn't. Either way, I hope this blogpost was useful to you in some way; maybe it inspired you to write more readable code, or maybe you were already doing that and it gave you some new ideas. Anyway, for any readable line of code you write; thanks from your future self and the other developers that might work on your project in the future!
As always, feel free to reach out if you have any feedback.
Florian